
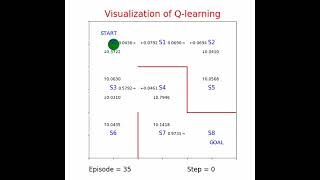
Q学習(Q learning)の状態価値Qを可視化してます。
ゴールしたら式1で報酬 R=1.0が与えられます。ゴールするまでは式2でQ値を更新します。γ=0.9, η=0.1, Qの初期値は(0≦乱数≦1)*0.1とします。
Q(s,a) = Q(s,a) + η*(R – Q(s_next,a_next)) …1
Q(s,a) = Q(s,a) + η*(γ*maxQ(s_next,:) – Q(s,a)) …2
式1からゴール直前のS7の値は1.0に収束するはずです。Q値が1に近づけば第2項が0にちかづくからです。S7直前のS4のQのmax値は1.0*γより0.9に、同様にS3は1.0*γ*γで0.81に、S0のmax値は0.729となるはずです。
動画で確かめてみました。
参考文献:深層強化学習 ⼩川雄太郎
Q学習 (Q learning) の状態価値 Q を可視化してます。迷路 Python
 学習
学習

コメント