
🧬 Reading FASTA Files with Python 💻
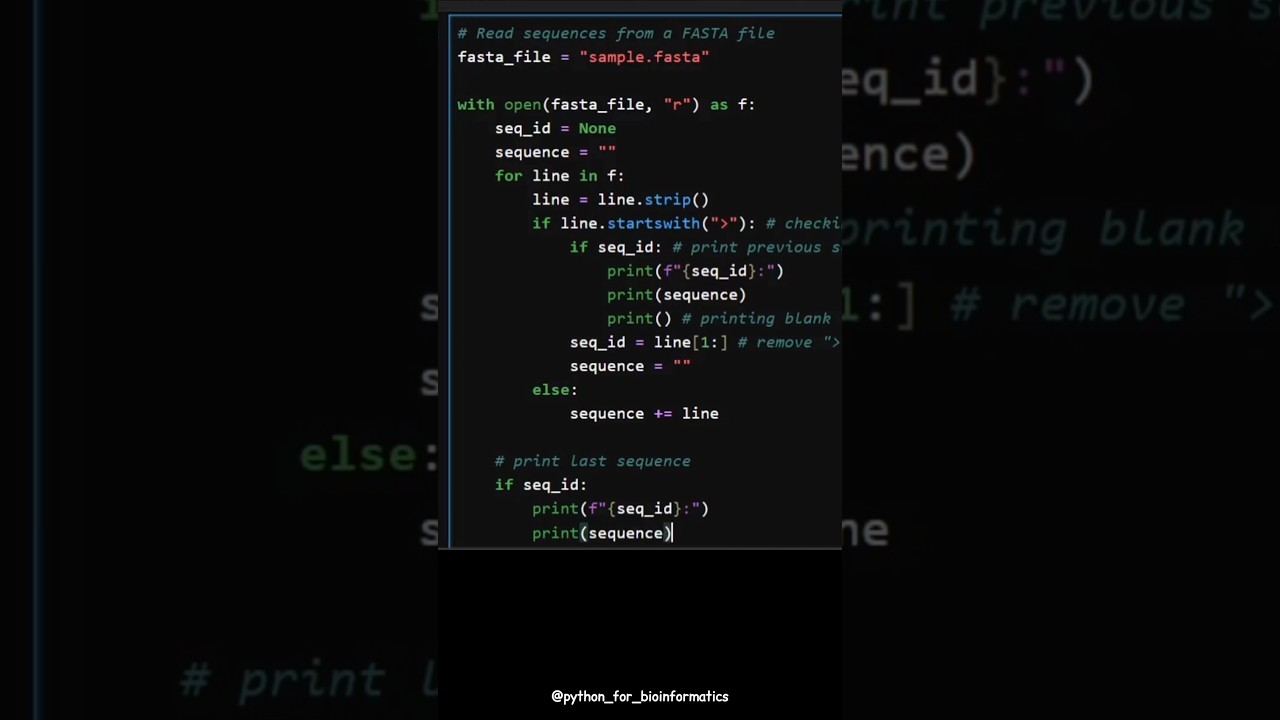
In bioinformatics, DNA and protein data is often stored in FASTA files, one of the most widely used formats in genomics and proteomics.
In this short tutorial, we break down:
✔️ What a FASTA file looks like (headers + sequences)
✔️ How to read it line by line using Python
✔️ How to separate sequence IDs from the DNA sequence
✔️ Printing the results in a clean format
This simple method is the foundation of many bioinformatics workflows, from sequence analysis, alignment, and genome assembly to protein studies.
Whether you’re a beginner in bioinformatics or practicing Python for life sciences, this is a great starting point to understand how data is structured and processed.
👉 Subscribe for more Python + Bioinformatics shorts!
#Python #Bioinformatics #FASTA #DNA #ComputationalBiology #PythonForBioinformatics #molecularbiology


コメント